


OpenAI Whisper - a neural net for speech to text
A practical guide to OpenAI Whisper for ASR applications


Background
With the development of unsupervised pre-training, exemplified by Wav2Vec 2.0 released in 2020, these models could learn directly from the raw audio without the need for human labels. So the raw training data could be scaled to 1 million hours very quickly. By fine-tuning the standard benchmarks (typically low-data setting) they yielded state-of-the-art results.
These pre-trained audio encoders learn high-quality representations of speech, but because they are purely unsupervised they lack an equivalent performant decoder mapping those representations to usable outputs, necessitating a fine-tuning stage to perform a task such as speech recognition.
Fine-tuning is another step and more often than not a complex process to make these models effective for the downstream tasks. All the more if the distribution of the input data changes the performance of the model degrades.
As per the OpenAI paper, "The goal of a speech recognition system should be to work reliably "out of the box" in a broad range of environments without requiring supervised fine-tuning of a decoder for every deployment distribution".
Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of weakly supervised speech recognition labeled audio data. It demonstrates that the model trained at this scale transfers well to existing datasets zero-shot, removing the need for any dataset-specific fine-tuning to achieve high-quality results.
The weakly supervised pre-training was done using joint multilingual and multitask training -
Multilingual - about 17 % of the training data is non-English and covers 96 other languages.
Multitask - the dataset also includes 18% of X -> en translation data.
Signal Processing
An audio signal in essence is the change of air pressure over time. So, the rate at which we sample this data denotes the sampling rate.
Since speech is continuous, it contains an infinite number of amplitude values. This poses problems for computer devices that expect finite arrays. Thus, we discretize our speech signal by sampling values from our signal at fixed time steps. The interval with which we sample our audio is known as the sampling rate and is usually measured in samples/sec or Hertz (Hz). Sampling with a higher sampling rate results in a better approximation of the continuous speech signal, but also requires storing more values per second.
Speech is often resampled to 16000 Hz. Resampling speech to 16000 Hz is a common practice that balances audio quality, file size, and compatibility with speech recognition and communication systems.
Let's try it out -
pip install librosa
Get a sample wave file from the web and try these few lines of code
import librosa
import librosa.display
import matplotlib.pyplot as plt
y, sr = librosa.load('./M1F1-Alaw-AFsp.wav')
resampled_signal = librosa.resample(y, orig_sr = sr, target_sr = 16000)
plt.plot(resampled_signal)
plt.title('Signal')
plt.xlabel('Time (samples)')
plt.ylabel('Amplitude')
Note in the above signal, we have only captured the resulting amplitude of the waveform (y-axis) over the time samples (x-axis). But a signal is comprised of several single-frequency sound waves. Fourier transform decomposes a signal into its individual frequencies and respective amplitude. Thus it converts a signal from the time domain to the frequency domain called the spectrum.
import numpy as np
n_fft = 2048
ft = np.abs(librosa.stft(resampled_signal[:n_fft], hop_length = n_fft+1))
plt.plot(ft)
plt.title('Spectrum')
plt.xlabel('Frequency Bin')
plt.ylabel('Amplitude')
The spectrogram is a bunch of FFTs stacked on top of each other. It is a way to visually represent a signal's loudness (amplitude) as it varies over time at different frequencies. Humans can perceive detecting differences in lower frequencies than in higher frequencies even if the distance between them is the same. This shows that humans do not perceive frequencies on a linear scale. Hence the scale used is a Mel scale and the spectrogram generated is called the Mel Spectrogram.
mel_spect = librosa.feature.melspectrogram(y=resampled_signal, sr=sr, n_fft=2048, hop_length=1024)
mel_spect = librosa.power_to_db(mel_spect, ref=np.max)
librosa.display.specshow(mel_spect, y_axis='mel', fmax=8000, x_axis='time')
plt.title('Mel Spectrogram')
plt.colorbar(format='%+2.0f dB')
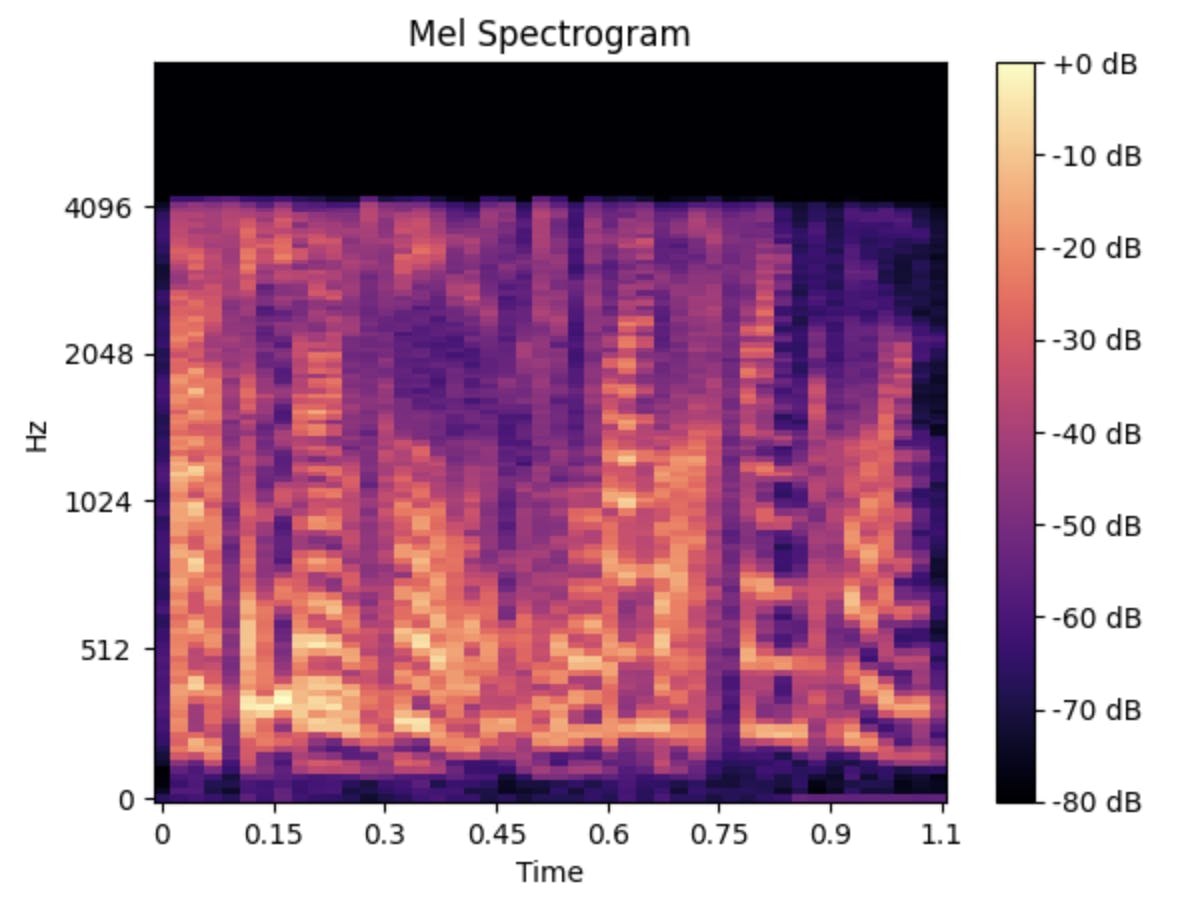
Mel channels are frequency bands that are spaced according to the Mel scale, which is a perceptual frequency scale based on the way humans perceive sound. Some examples of Mel channels include:
The lowest Mel channel might cover frequencies between 0 and 100 Hz, capturing low-frequency sounds like bass notes in music or the rumble of a vehicle engine.
Mid-range Mel channels might cover frequencies between 1,000 and 3,000 Hz, capturing the range of human speech or the mid-range frequencies of a musical instrument like a guitar or piano.
Higher Mel channels might cover frequencies between 10,000 and 20,000 Hz, capturing high-frequency sounds like the hiss of a cymbal or the whistle of a bird.
With this basic understanding of signal processing let's understand the architecture of Whisper.
Architecture of Whisper

Broadly the Whisper architecture is as follows -
It is an encoder-decoder transformer architecture.
The input audio is split into 30-second chunks paired with the subset of the transcript that occurs within that time segment.
All audio is re-sampled to 16,000 Hz.
The re-sampled audio is used to create an 80-channel log-magnitude Mel spectrogram representation which is computed on 25-millisecond windows with a stride of 10 milliseconds.
Feature normalization by scaling the input to be between -1 and 1 with approx zero mean.
The encoder processes this input representation using two convolution layers with the GELU activation.
Sinusoidal position embeddings are added and passed to the encoder Transformer blocks.
The transformer uses pre-activation residual blocks and the final layer normalization is applied to the encoder input.
The decoder uses learned position embeddings and tied input-output token representations.
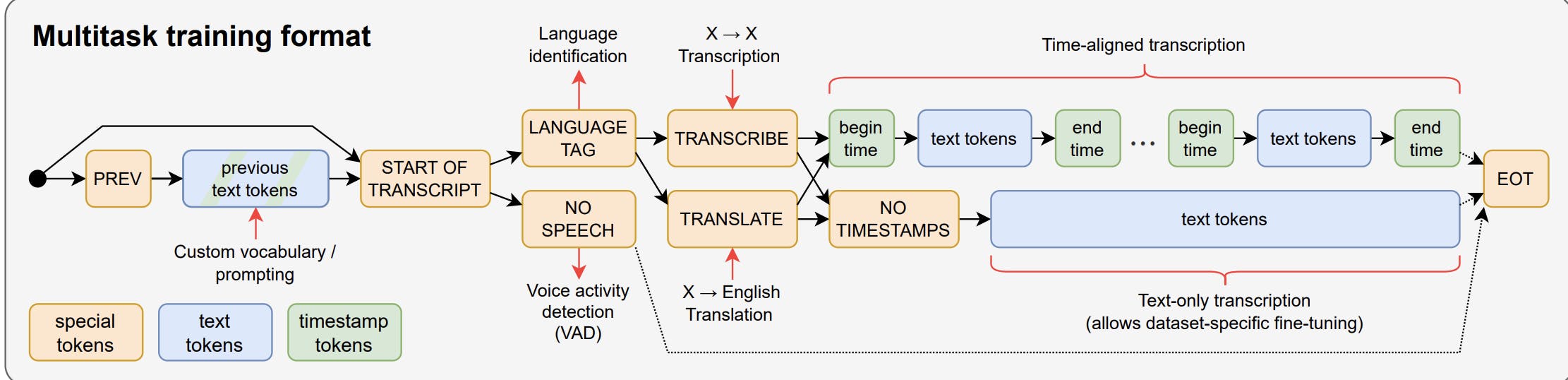
Multitask Training
Whisper is a fully featured speech recognition system that can do the following tasks on the same input audio signal -
Transcription
Translation
Voice activity detection
Speaker diarization
Inverse text normalization
Alignment
Language identification
All of these tasks are jointly represented as a sequence of tokens to be predicted by the decoder, allowing a single model to execute the entire speech-processing pipeline. Here is how the input looks like in the decoder (multitask training format)
Whisper’s zero-shot performance across many diverse datasets makes fewer errors than existing models. Detailed performance metrics are present in the paper.
Long-form Transcription
Whisper models are trained on 30-second audio chunks and cannot consume longer audio inputs at once. In real-world applications often you need to transcribe an hour-long audio.
The strategy used for this is to perform buffered transcription of long audio and shift the window according to the timestamps predicted by the model. Empirically it is crucial to have beam search and temperature scheduling based on repetitiveness and log probability of the model predictions to reliably transcribe long audio.
Here are a few implementation details based on the paper -
Using beam search with 5 beams using the log probability as the score function, to reduce repetition looping which happens more frequently in greedy decoding.
Start with temperature 0 (i.e. always selecting the tokens with the highest probability) and increase the temperature by 0.2 up to 1.0 when either the average log probability over the generated tokens is lower than -1 or generated text has a gzip compression rate higher than 2.4
Providing the transcribed text from the preceding window as previous-text conditioning when the applied temperature is below 0.5 further improves the performance.
Whisper on Huggingface
To transcribe an audio sample the model needs the WhisperProcessor to -
Pre-process the audio inputs (converting them to log-Mel spectrogram for the model)
Post-process the model outputs (converting them from token to text)
The model is informed of which task to perform (transcription or translation) by passing the appropriate "context tokens". These context tokens are a sequence of tokens that are given to the decoder at the start of the decoding process, and take the following order -
The transcription always starts with the <|startoftranscript|> token
The second token is the language token (e.g. <|en|> for English)
The third token is the "task token". It can take one of two values, <|transcribe|> for speech recognition or <|translation|> for speech translation.
In addition, a <|notimestamps|> token is added if the model should not include timestamp prediction.
So, a typical sequence of context tokens might look like as follows -
<|startoftranscript|> <|en|> <|transcribe|> <|notimestamps|>
which tells the model to decode in English, under the task of speech recognition, and not to predict timestamps.
These tokens can either be forced or un-forced. If they are forced, the model is made to predict each token at each position. This allows one to control the output language and task for the Whisper model. If they are un-forced, the Whisper model will automatically predict the output language and task itself.
The context tokens are set in this fashion -
model.config.forced_decoder_ids = WhisperProcessor.get_decoder_prompt_ids(language="english", task="transcribe")
The above context tokens force the model to predict in English under the task of speech recognition.
Code Examples
Transcribe Audio to English Text
We will pick a dataset from LibriSpeech, and using Whisper we will transcribe the audio to English text. Check the Colab Notebook.
Transcription of English audio to English text (Unforced)
Here the context tokens are "unforced", so the model automatically predicts the output language (English) and task (transcribe). Check the Colab Notebook
Transcription of French audio to French Text (forced)
Here the context tokens are "forced". Check the Colab Notebook
Translation of French audio to English Text
Setting the task to "translate" forces the Whisper model to perform speech translation. In the above notebook set the
forced_decoder_idsas followsforced_decoder_ids = processor.get_decoder_prompt_ids(language="french", task="translate")Long-Form Transcription
The Whisper model is intrinsically designed to work on audio samples of up to 30 sec in duration. However, by using a chunking algorithm, it can be used to transcribe audio samples of up to the arbitrary length. Check the Colab Notebook.
Python WebApp for Transcribe
Python app, that records your voice and also transcribes it instantly using the OpenAI Whisper API. Check the source code
Fine-Tune Whisper for Multilingual ASR with Transformers
The extensive multilingual ASR knowledge acquired by Whisper during pre-training can be leveraged for other low-resource languages, through fine-tuning, the pre-trained checkpoints can be adapted for specific datasets and languages to further improve upon these results. In this code, I am using the Common Voice dataset (mozilla-foundation/common_voice_13_0) and for the language, I have selected Hindi (hi). Check this Colab Notebook. The model is hosted on HuggingFace : https://huggingface.co/suvrobaner/whisper-small-finetuned-hi-commonvoice
Interactive Demo App with Gradio
Here, is the Google Colab. Check this app made using Gradio and hosted on Spaces.
Author's Note
I hope this article will help many practitioners who want to use Whisper for their ASR applications. I also love solving problems related to NLP and Deep Learning. If you wish to collaborate please reach out to me through my LinkedIn profile.
In the end, want to thank the Open source community for being so kind, helpful and empowering to shape our respective professional journeys.